騰訊混元大模型團隊宣布開源最新視頻生成模型HunyuanVideo5,這是一款基于DiffusionTransformer(DiT)架構、參數為3B的輕量級視頻生成模型,支持生成5-10秒的高清視頻。
2025年9月19日,阿里云宣布通義萬相全新動作生成模型Wan2-Animate正式開源。該模型能夠驅動人物、動漫形象和動物照片,廣泛應用于短視頻創作、舞蹈模板生成、動漫制作等領域。用戶可以在GitHub、HuggingFace和魔搭社區下
谷歌最新的視頻生成模型Veo3即將在GooglePhotos中正式上線。這一新功能將通過移動應用的"創建"標簽頁為美國用戶提供服務,允許用戶將靜態圖像轉換為視頻片段。
8月28日,騰訊混元宣布開源端到端視頻音效生成模型HunyuanVideo-Foley,這一模型能夠通過輸入視頻和文字為視頻匹配電影級音效,為視頻創作帶來了新的突破。
8月27日,愛詩科技公司宣布PixVerseV5模型全球同步上線,同時拍我AI(PixVerse)全球用戶規模突破1億。
面對中國在開源人工智能領域的強勢崛起,美國本周一正式啟動名為"ATOM計劃"的新戰略,旨在重奪開源AI領域的全球領導地位。
MiniMax今日宣布推出新一代語音生成模型Speech5,這一升級版模型在全球語音技術領域再次樹立了新的標桿,進一步鞏固了其作為全球最強語音模型的地位。Speech5在多語種表現力、音色復刻以及語種覆蓋范圍等方面均實現了顯
近日,阿里語音AI團隊宣布開源全球首個支持鏈式推理的音頻生成模型ThinkSound,該模型通過引入思維鏈(Chain-of-Thought)技術,突破傳統視頻轉音頻技術對畫面動態捕捉的局限,實現高保真、強同步的空間音頻生成。這一突破標志
近日,QwenVLo多模態大模型正式發布,該模型在圖像內容理解與生成方面取得了顯著進展,為用戶帶來了全新的視覺創作體驗。
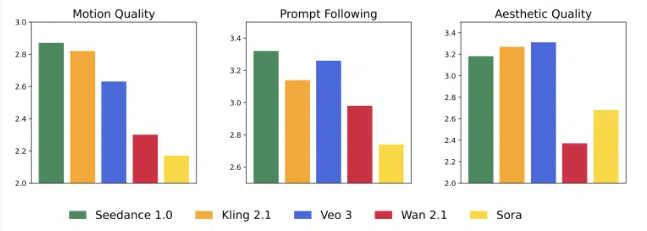
在近期的人工智能視頻生成領域,字節跳動(TikTok 的母公司)悄然發布了一款名為 Seedance1.0的新模型,該模型在獨立的評測中已經超越了谷歌最新推出的 Veo3。
稀宇科技在視頻生成領域取得新進展,正式推出全新視頻生成模型Hailuo02。
近日,百度聯合復旦大學等發布Hallo2,一個可以生成長達數小時且分辨率為4K的人物動畫的視覺模型。
Lumiere是谷歌發布的第三個視頻生成模型,這次的模型演示視頻質量非常高,運動幅度和一致性表現也很好。除了視頻生成,該模型還支持各種視頻編輯和生成控制能力。
-------------沒有了-------------
傾城
小新
葉紫
創維電視(SKYWORTH)55V40
小米全面屏電視E43K
康佳(KONKA)55D6S
榮泰S60按摩椅


































 產品與服務
產品與服務
 聯系站長
聯系站長
 關于我們
關于我們