據AIbase報道,一項名為“CritPt”的全新物理基準測試結果顯示,即使是目前最頂尖的人工智能模型,如Gemini3Pro和GPT-5,距離成為真正的自主科學家仍有巨大的差距。
近日,美團LongCat團隊推出了一個名為UNO-Bench的全新基準測試,旨在系統性地評估這些模型在不同模態下的理解能力。
近日,OSWorld團隊正式發布了OSWorld-MCP,這是首個針對計算機使用代理產品進行全面評估的基準測試工具。該基準旨在為開發者和用戶提供真實環境下的產品能力評測,提升了評估的真實度、平衡性與可比性。
近日,美團LongCat團隊正式發布了一項名為VitaBench的智能體評測基準,旨在針對多交互任務,特別是在復雜生活場景中的應用。VitaBench的推出為智能體在真實生活場景中的研發提供了重要基礎設施。
Adobe最近宣布推出一項新服務——AdobeAIFoundry,旨在為企業客戶提供定制化的AI模型Firefly。
上海人工智能實驗室與浙江大學等機構近日聯合推出IWR-Bench,這是首個專門評估大語言模型將視頻轉化為交互式網頁代碼能力的基準測試。
近日,一項名為RoboChallenge的基準測試平臺正式發布,旨在為機器人領域提供首個大規模、多任務且在真實物理環境中由真實機器人執行操作任務的評估標準。
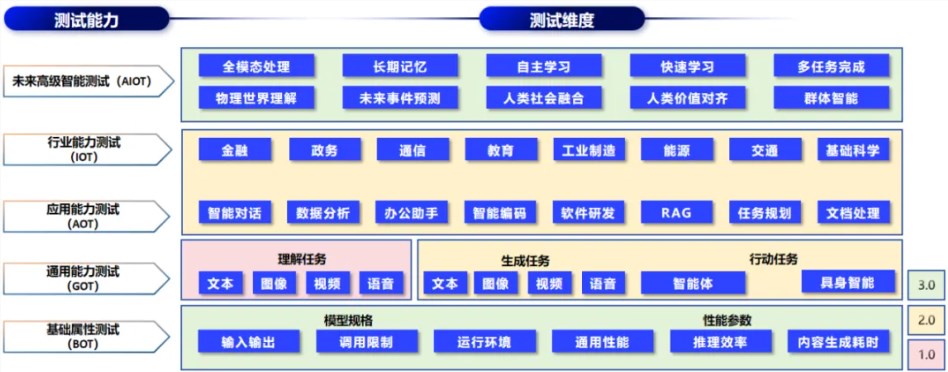
近日,中國信息通信研究院(信通院)正式推出了“方升”基準測試體系0,標志著國內人工智能(AI)評測的又一重大進步。
在最新發布的Moondream0預覽版中,這款以高效混合專家(MoE)架構為基礎的模型展示了令人驚嘆的視覺推理能力。
近日,OpenAI推出了一項新的基準測試,旨在評估其人工智能模型在各行業與人類專業人士的表現差異。這項名為GDPval的測試,是OpenAI對其人工智能系統在經濟價值工作中是否能超越人類的重要探索。
7月28日,在世界人工智能大會論壇上,螞蟻數科正式發布金融推理大模型Agentar-Fin-R1,為金融AI應用打造“可靠、可控、可優化”的智能中樞。Agentar-Fin-R1基于Qwen3研發,在FinEvalFinanceIQ等權威金融大模型評測基準上超越
去年12月,英特爾前首席執行官帕特?基辛格(PatGelsinger)結束了他在半導體巨頭的40多年職業生涯,許多人對此充滿期待,紛紛猜測他接下來的計劃。就在近日,這位業界領袖揭開了他的下一步:致力于確保人工智能模型能有效促進
近日,MiniMax 推出了其視頻人工智能模型 Hailuo02的第二代版本,帶來了性能和價格上的重大升級。
近日,馬里蘭大學發布了一項重要研究,針對GPT-4V視覺模型進行了首個專為其設計的基準測試,名為HallusionBench。
-------------沒有了-------------
傾城
小新
葉紫
創維電視(SKYWORTH)55V40
小米全面屏電視E43K
康佳(KONKA)55D6S
榮泰S60按摩椅





























 產品與服務
產品與服務
 聯系站長
聯系站長
 關于我們
關于我們