

前段時(shí)間,微軟公布并開(kāi)源了最新一代大模型WizardLM-2,號(hào)稱性能堪比GPT-4。不過(guò),還未上線一天,模型權(quán)重和公告全被刪除了,原因竟是......
上周,微軟空降了一個(gè)堪稱GPT-4級(jí)別的開(kāi)源模型WizardLM-2。
卻沒(méi)想到發(fā)布幾小時(shí)之后,立馬被刪除了。
有網(wǎng)友突然發(fā)現(xiàn),WizardLM的模型權(quán)重、公告帖子全部被刪除,并且不再微軟集合中,除了提到站點(diǎn)之外,卻找不到任何證據(jù)證明這個(gè)微軟的官方項(xiàng)目。

GitHub項(xiàng)目主頁(yè)已成404。
包括模型在HF上的權(quán)重,也全部消失了.....

全網(wǎng)滿臉疑惑,WizardLM怎么沒(méi)了?

然鵝,微軟之所以這么做,是因?yàn)閳F(tuán)隊(duì)內(nèi)部忘記對(duì)模型做「測(cè)試」。
隨后,微軟團(tuán)隊(duì)現(xiàn)身道歉并解釋道,自幾個(gè)月前WizardLM發(fā)布以來(lái)有一段時(shí)間,所以我們對(duì)現(xiàn)在新的發(fā)布流程不太熟悉。
我們不小心遺漏了模型發(fā)布流程中所需的一項(xiàng)內(nèi)容 :投毒測(cè)試
微軟WizardLM升級(jí)二代
去年6月,基于LlaMA微調(diào)而來(lái)的初代WizardLM一經(jīng)發(fā)布,吸引了開(kāi)源社區(qū)一大波關(guān)注。

論文地址:https://arxiv.org/pdf/2304.12244.pdf
隨后,代碼版的WizardCoder誕生——一個(gè)基于Code Llama,利用Evol-Instruct微調(diào)的模型。
測(cè)試結(jié)果顯示,WizardCoder在HumanEval上的pass@1達(dá)到了驚人的 73.2%,超越了原始GPT-4。

時(shí)間推進(jìn)到4月15日,微軟開(kāi)發(fā)者官宣了新一代WizardLM,這一次是從Mixtral 8x22B微調(diào)而來(lái)。
它包含了三個(gè)參數(shù)版本,分別是8x22B、70B和7B。

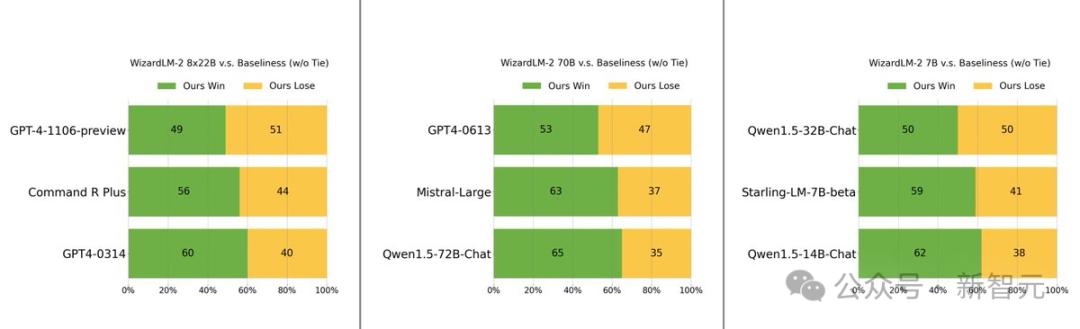
最值得一提的是,在MT-Bench基準(zhǔn)測(cè)試中,新模型取得了領(lǐng)先的優(yōu)勢(shì)。

具體來(lái)說(shuō),最大參數(shù)版本的WizardLM 8x22B模型性能,幾乎接近GPT-4和Claude 3。
在相同參數(shù)規(guī)模下,70B版本位列第一。
而7B版本是最快的,甚至可以達(dá)到與,參數(shù)規(guī)模10倍大的領(lǐng)先模型相當(dāng)?shù)男阅堋?/p>
WizardLM 2出色表現(xiàn)的背后的秘訣在于,微軟開(kāi)發(fā)的革命性訓(xùn)練方法論Evol-Instruct。
Evol-Instruct利用大型語(yǔ)言模型,迭代地將初始指令集改寫成越來(lái)越復(fù)雜的變體。然后,利用這些演化指令數(shù)據(jù)對(duì)基礎(chǔ)模型進(jìn)行微調(diào),從而顯著提高其處理復(fù)雜任務(wù)的能力。
另一個(gè)是強(qiáng)化學(xué)習(xí)框架RLEIF,也在WizardLM 2開(kāi)發(fā)過(guò)程中起到了重要作用。
在WizardLM 2訓(xùn)練中,還采用了AI Align AI(AAA)方法,可以讓多個(gè)領(lǐng)先的大模型相互指導(dǎo)和改進(jìn)。
AAA框架由兩個(gè)主要的組件組成,分別是「共同教學(xué)」和「自學(xué)」。
共同教學(xué)這一階段,WizardLM和各種獲得許可的開(kāi)源和專有先進(jìn)模型進(jìn)行模擬聊天、質(zhì)量評(píng)判、改進(jìn)建議和縮小技能差距。
通過(guò)相互交流和提供反饋,模型可向同行學(xué)習(xí)并完善自身能力。
對(duì)于自學(xué),WizardLM可通過(guò)主動(dòng)自學(xué),為監(jiān)督學(xué)習(xí)生成新的進(jìn)化訓(xùn)練數(shù)據(jù),為強(qiáng)化學(xué)習(xí)生成偏好數(shù)據(jù)。
這種自學(xué)機(jī)制允許模型通過(guò)學(xué)習(xí)自身生成的數(shù)據(jù)和反饋信息來(lái)不斷提高性能。
另外,WizardLM 2模型的訓(xùn)練使用了生成的合成數(shù)據(jù)。
在研究人員看來(lái),大模型的訓(xùn)練數(shù)據(jù)日益枯竭,相信AI精心創(chuàng)建的數(shù)據(jù)和AI逐步監(jiān)督的模型將是通往更強(qiáng)大人工智能的唯一途徑。
因此,他們創(chuàng)建了一個(gè)完全由AI驅(qū)動(dòng)的合成訓(xùn)練系統(tǒng)來(lái)改進(jìn)WizardLM-2。

手快的網(wǎng)友,已經(jīng)下載了權(quán)重
然而,在資料庫(kù)被刪除之前,許多人已經(jīng)下載了模型權(quán)重。
在該模型被刪除之前,幾個(gè)用戶還在一些額外的基準(zhǔn)上進(jìn)行了測(cè)試。

好在測(cè)試的網(wǎng)友對(duì)7B模型感到印象深刻,并稱這將是自己執(zhí)行本地助理任務(wù)的首選模型。

還有人對(duì)其進(jìn)行了投毒測(cè)試,發(fā)現(xiàn)WizardLM-8x22B的得分為98.33,而基礎(chǔ)Mixtral-8x22B的得分為89.46,Mixtral 8x7B-Indict的得分為92.93。
得分越高越好,也就是說(shuō)WizardLM-8x22B還是很強(qiáng)的。

如果沒(méi)有投毒測(cè)試,將模型發(fā)出來(lái)是萬(wàn)萬(wàn)不可的。
大模型容易產(chǎn)生幻覺(jué),人盡皆知。
如果WizardLM 2在回答中輸出「有毒、有偏見(jiàn)、不正確」的內(nèi)容,對(duì)大模型來(lái)說(shuō)并不友好。
尤其是,這些錯(cuò)誤引來(lái)全網(wǎng)關(guān)注,對(duì)與微軟自身來(lái)說(shuō)也會(huì)陷入非議之中,甚至?xí)划?dāng)局調(diào)查。
有網(wǎng)友疑惑道,你可以通過(guò)「投毒測(cè)試」更新指標(biāo)。為什么要?jiǎng)h除整個(gè)版本庫(kù)和權(quán)重?
微軟作者表示,根據(jù)內(nèi)部最新的規(guī)定,只能這樣操作。

還有人表示,我們就想要未經(jīng)「腦葉切除」的模型。

不過(guò),開(kāi)發(fā)者們還需要耐心等待,微軟團(tuán)隊(duì)承諾,會(huì)在測(cè)試完成后重新上線。















銷視頻")










 產(chǎn)品與服務(wù)
產(chǎn)品與服務(wù)
 聯(lián)系站長(zhǎng)
聯(lián)系站長(zhǎng)
 關(guān)于我們
關(guān)于我們